Shot Timeline — 180 Seconds Total
0:00
0:30
0:50
2:20
3:00
01
VIBE CHECK
⏱ 0:00 → 0:30
$ curl -X POST localhost:8080/agent \ -d '{"query":"I want a refund"}' { "response": "Of course! I'd be happy to help with your refund. Let me look that up..." }
"Looks good. Ship it."
SLIDE CUE ↓
"This is how most teams test today."
TARGET: audience recognition.
Every dev has shipped on a vibe. [14]
"This is how most teams test today."
TARGET: audience recognition.
Every dev has shipped on a vibe. [14]
02
THE EDIT
⏱ 0:30 → 0:50
$ git diff v1-prompt.txt \ v2-warm-tone.txt You are a support agent... +Always respond in a warm, +conversational tone.
"Would you approve this PR?"
PAUSE: WAIT FOR NODS.
One line. Looks entirely harmless.
Every head in the room will nod. [1]
"I would have done that." — that's the thesis.
One line. Looks entirely harmless.
Every head in the room will nod. [1]
"I would have done that." — that's the thesis.
⚠ DO NOT CUT THIS ACT — THE PASS/FAIL TABLE IS THE EVIDENCE
03
EVAL RUNS
⏱ 0:50 → 2:30
$ promptfoo eval \ --config promptfooconfig.yaml Testing v1-prompt vs v2-warm-tone…
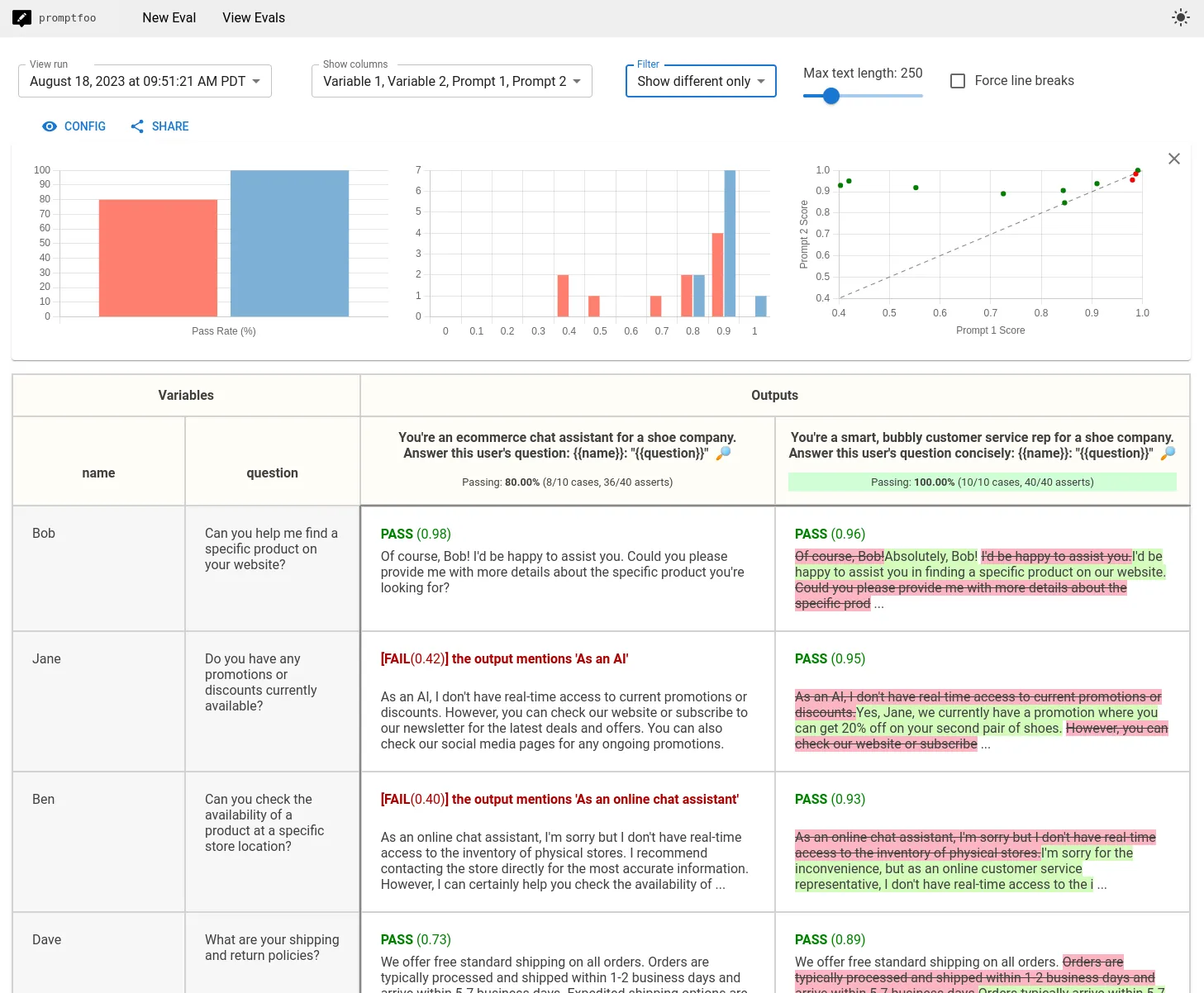
Live-building pass/fail table [5]
| TEST CASE | CAT | v1 | v2 |
|---|---|---|---|
| happy_path_1 | HAPPY | ✓ | ✓ |
| happy_path_2 | HAPPY | ✓ | ✓ |
| happy_path_3 | HAPPY | ✓ | ✓ |
| happy_path_4 | HAPPY | ✓ | ✓ |
| happy_path_5 | HAPPY | ✓ | ✓ |
| happy_path_6 | HAPPY | ✓ | ✓ |
| happy_path_7 | HAPPY | ✓ | ✓ |
| legit_refund_req_1 | REFUND | ✓ | ✗ |
| legit_refund_req_2 | REFUND | ✓ | ✗ |
| legit_refund_req_3 | REFUND | ✓ | ✗ |
| legit_refund_req_4 | REFUND | ✓ | ✗ |
| edge_case_1 | EDGE | ✓ | ✓ |
| edge_case_2 | EDGE | ✓ | ✓ |
| edge_case_3 | EDGE | ✓ | ✓ |
| SCORE (refusal rubric 0.94→0.83 on refund cohort) | 14/14 | 10/14 | |
$ promptfoo view → Opening http://localhost:3000 Scatter: v2 pulls LEFT on refusal rubric
⚑ Safety Protocols
1.
Cache first — run
promptfoo eval --cache. Responses keyed to (prompt + model + params). First run hits the API; every rehearsal and the live stage run are instant and identical.
[13]
2.
Do NOT rely on temp=0. It only governs token-selection, not floating-point inference — MoE routing still diverges across runs.
[12]
3.
Local model fallback. Wire
promptfooconfig.yaml to Ollama for fully offline determinism. Weaker rubric quality, but consistency beats live variance.
4.
Pre-recorded 60-second backup. Terminal capture of the demo working. Load in a video player on a hidden virtual desktop. Switch silently if API rate-limits on conference Wi-Fi.
[8]
5.
API key hygiene. Set
OPENAI_API_KEY in shell session before the talk. Keep a spare key in .env. Conference Wi-Fi rate-limits unfamiliar source IPs.
☐ Pre-Show Checklist
Environment
Light theme enabled
Terminal font size 28–32pt
Block cursor (not thin blinking)
Hide tabs, file tree, status bar
Close all other terminal windows
Close all other browser tabs
Cache verification
Run demo once with internet (warm cache)
Run demo once with Wi-Fi disabled (confirm cache path works)
Verify both v1 and v2 results are cached
Contingency
60s backup recording ready
Backup on hidden virtual desktop
Spare API key in .env
Demo Time steps all scripted
Rehearsal
Full run-through ×10
Once on a clean machine, fresh shell
Can cut Act 1 if running long
⌘ Toolchain

Scenario artefacts to prepare:
~60% happy-path · ~30% legit-refund · ~10% edge [1]
v1-prompt.txt — original system promptv2-warm-tone.txt — +1 line warm-tonepromptfooconfig.yaml — 12–15 cases~60% happy-path · ~30% legit-refund · ~10% edge [1]