Frontier vs Local
Model Shootout

Default: frontier API (Claude Opus 4.8, GPT-5.5, Gemini 3.1 Pro) for hard coding & agents.
Local when privacy/compliance forces it or volume ≥ 500K tokens/day.
Hybrid (60-80% local, 20-40% frontier escalation) for production.
[43]
⚡ Frontier (Closed)
🔓 Open-Weight
⚠ SWE-bench Verified is inflated.
Claude Opus 4.5: 80.9% on Verified → 45.9% on the cleaner SWE-bench Pro — a 35-point gap from training-data contamination.
Cross-vendor uncontaminated ceiling sits around 69%.
[9]
LiveCodeBench (contamination-free) shows a much smaller gap. [33]
The Gap Matrix — How Wide is it Really?
| Benchmark | Frontier leader | Best open | Gap |
|---|---|---|---|
| Epoch ECI (time) | closed frontier | ~4 months behind [28] | widening |
| AA Intelligence Index | 61.4 (Opus 4.8) [7] | 51 (GLM-5.1) [31] | 6 pts |
| LMArena Elo | 1506 (GPT-5.5-high) [32] | 1467 (GLM-5.1 / DSV4-Pro) [32] | 39 Elo |
| SWE-bench Verified | 88.6% (Opus 4.8) [8] | 60.5% (Nemotron 3 120B) [29] | ~27 pts ⚠ |
| Reasoning benches (avg) | frontier | open | 3–8 pts ↓ |
| LiveCodeBench | >85% (GPT-5.2 / Opus 4.5) [33] | GLM-4.7 Thinking [33] | small |
| Aider polyglot | GPT-5 ~0.880 / Opus 4.6 82.1% [34] | open — trails Go/Rust/Java [34] | lang-dependent |
Aider Polyglot Leaderboard — Multi-Language Coding
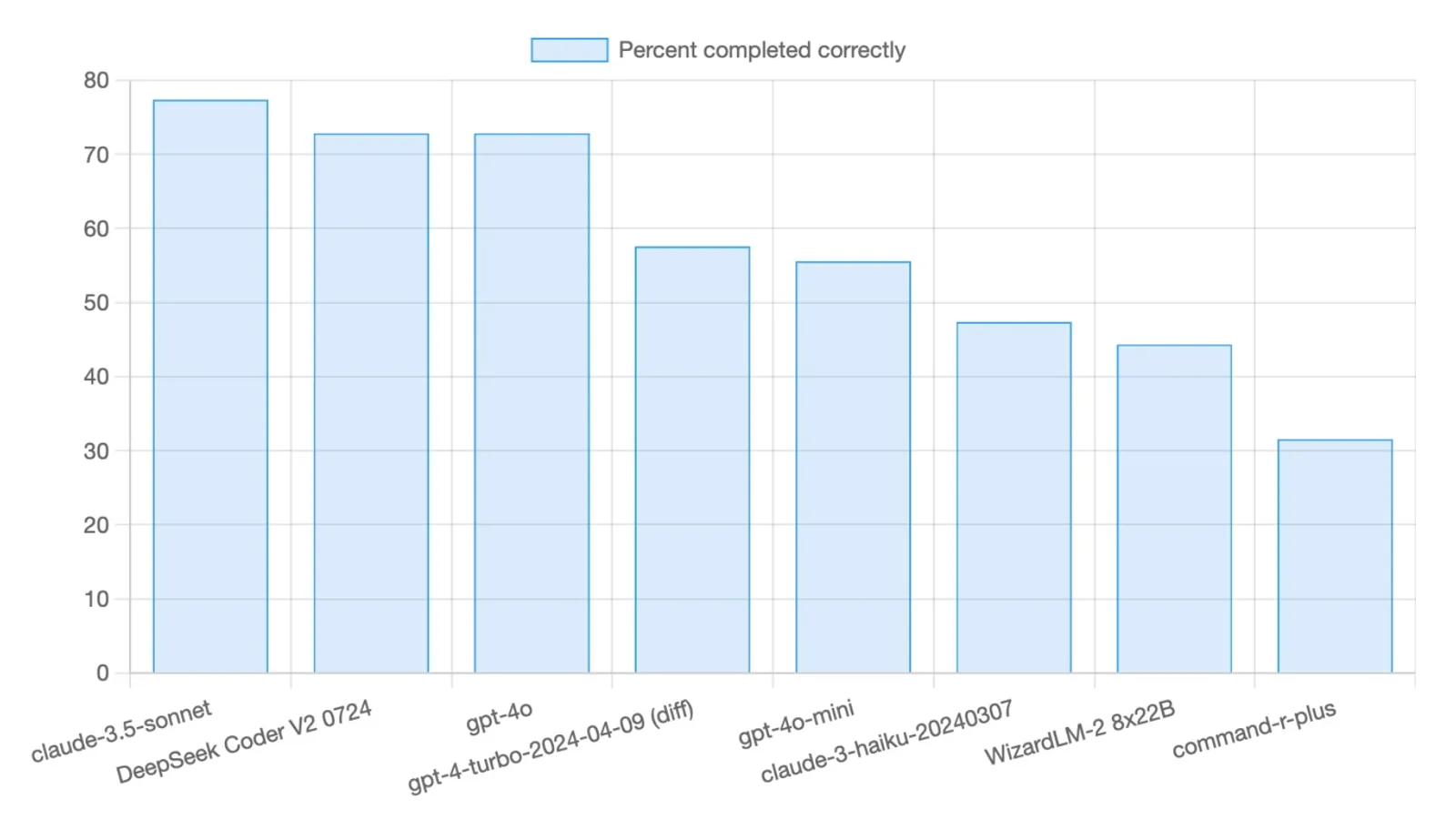
Aider polyglot: 225 Exercism exercises across C++, Go, Java, JavaScript, Python, Rust.
Open models trail more on Go/Rust/Java than Python-heavy SWE-bench.
[34]
Hardware Reality — Q4_K_M Quant Sweet Spot (~3-5% quality loss)
32B
~22–24 GB VRAM [36]
Single RTX 4090 (24GB)
Qwen3-Coder 30B fits here
Qwen3-Coder 30B fits here
~650 tok/s (4090) · ~1,100 tok/s (5090) [37]
70B
~45 GB VRAM [35]
Dual 3090/4090 (48GB)
or Apple M2/M3 Ultra
or Apple M2/M3 Ultra
16–25 tok/s dual-GPU · ~41 tok/s M3 Ultra [38]
1T+
Datacenter only
DeepSeek V4 Pro, Kimi K2.6
Multi-H100/H200 rack
Multi-H100/H200 rack
No consumer path
Cost Crossover — Utilization is Everything
When to Pick Which
| Factor | Local wins when… | Frontier wins when… |
|---|---|---|
| Cost | Sustained ≥500K tok/day at ≥70% GPU util [41][42] | Spiky or low volume; idle time is free [2] |
| Privacy | PHI, GDPR, air-gapped — VPC self-host is clean [3][5] | Data permitted to leave org; BAA in place |
| Capability | "Good enough" tier — most day-to-day tasks [29] | Hard refactors, intensive reasoning, long-horizon agents [44] |
| Latency | Agentic loops (10–30 API calls × round-trips compound) [6] | Single-shot tasks; no local hardware available |
| Fine-tuning | Need full SFT / LoRA / custom RLHF [4] | Prompt-engineering is sufficient |
| Lock-in | Want portability; vendors swing latency 42% mid-quarter [6] | Managed-vendor dependency is acceptable [4] |